從混亂到優雅,讓專案不再失控:ATDD 與 Clean Architecture 的後端實戰之路
你是不是也遇過這種情況?每當專案多一個新功能,整個系統就像被隕石砸到一樣,到處都是坑,永遠補不完。這次很高興能和我實習的同事 Dong 一起在 COSCUP 中,向大家分享,我們是怎麼從「隕石式開發」走到擁抱 ATDD 和 Clean Architecture。
2025-08-15一切混亂的起源
首先,要先向大家介紹一種開發模式:隕石式開發。
8/7 星期四
PM: 我們要加入一個新的 OOO 功能,上線後一定能賺大錢!
Dev: 什麼時候要?
PM: 問就是 ASAP,明天~
Dev: 🤯
---
8/8 星期五
Dev: 我們剛剛將新功能上線了
QA: 出現了 XXX 問題,是這個版本開始的
Dev: 找到 XXX 的 root cause 了,剛推了 hotfix
QA: 呃……又出問題了
為什麼會發生這樣的狀況,好像整個程式禁不起任何一點變更?不外乎堆積如山的技術債、缺乏可測試性,而且各功能間高度耦合。當然這些問題我們都知道要避免,但也同時會疑惑:
要多少測試才算足夠?
要多乾淨的 Code 才能將叫做 Clean Code?
這是個大哉問。根據每個專案的性質和規模,有不同的答案。但如果你心中還沒有想法,不妨接著看下去,哪些方法就算在大型專案面前也能輕鬆應付。
要多少測試才足夠?
先畫靶再射箭的 TDD
單元測試是一個能幫助我們保護程式碼的行為,透過撰寫一系列的輸入以及正確的輸出,來確認程式的運作符合預期。不過如果我們先完成實作,才去寫測試,就好像是看著考卷答案出題目,覺得沒有意義而且浪費時間。
但如果我們先寫測試呢?這就是 TDD (Test Driven Development),測試驅動開發。其實每個人都接觸過這種開發的形式,像是演算法練習平台,我們得通過那一系列的測資,才算是正確的完成題目需求。
然而真實世界的情況通常更複雜,而且先畫的這個靶,是不是跟 PM 或是客戶所期望的一致呢?如果先寫的測試只涵蓋到需求的一部分,最後勢必會遇到一堆問題;如果測試太過嚴苛,又會浪費開發的量能和時間。追根究底的原因就是,開發者、QA、PM 或客戶三者並沒有聚在一起好好地討論,怎樣叫做完成。
ATDD 驗收測試驅動開發
傳統的單元測試,可能會太過針對實作細節,儘管通過了單元測試,整支程式是否符合需求仍是個問號。問題在於測試不應該只是為程式碼服務,而是應該為需求服務。TDD 先畫靶再射箭的精神是好的,但我們還需要讓這個靶是畫在需求上,如此以軟體最終驗收情境作為測試,便是 ATDD (Acceptance Test Driven Development),驗收測試驅動開發。
ATDD 的精神不只是專注在測試本身,更在於開發過程中各角色對於需求的共識。透過驗收測試這樣共同的語言,讓開發的產物不再偏離目標,而 Gherkin Syntax 則可以很好的扮演這個共同的語言。
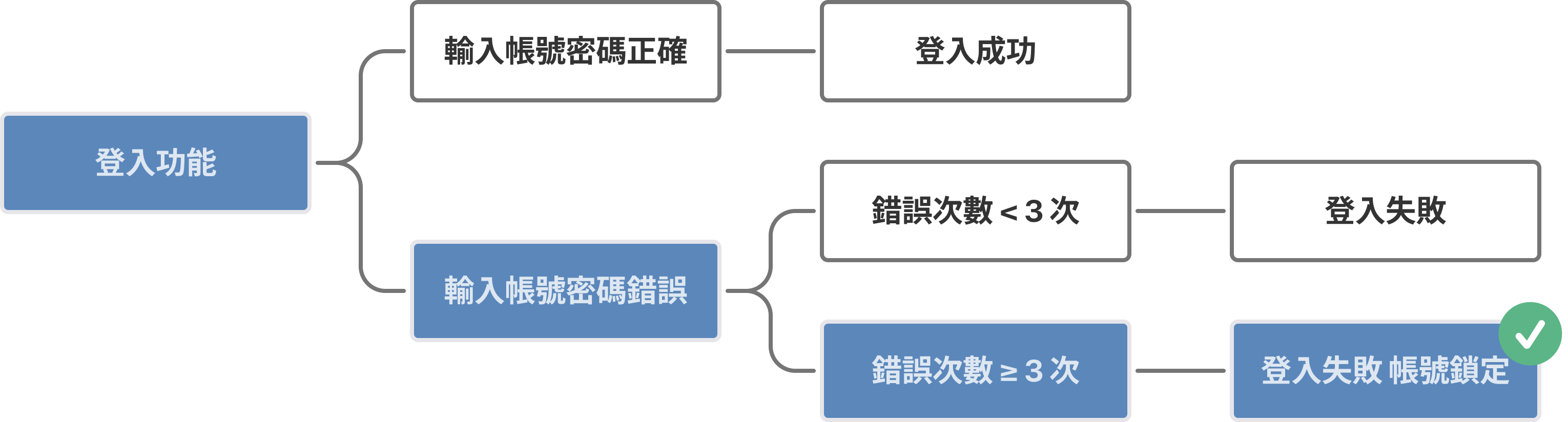
舉一個使用者登入的例子。使用者登入可能會有相當多種情況:帳號密碼輸入正確、找不到帳號要引導至註冊頁、密碼錯誤太多次要鎖定帳號……。我們可以用 Gherkin Syntax: Given-When-Then 的架構,讓這些情境變成清晰且格式化的敘述,例如:
Given 一個已存在的帳號
When 使用者輸入錯誤的帳密
And 連續錯誤的次數為 5 次
Then 回傳錯誤訊息
And 將帳號鎖定
另外,我們也可以將各個情境透過 flow chart 串連起來,如此一來便能以更直觀的方式向他人展示完整的功能,或是當前實作的項目為何。
要多乾淨的 Code 才能將叫做 Clean Code?
除了註解、變數命名等 coding style 要乾淨,架構也要乾淨。正好有個架構名字本身就有乾淨,它就是 Clean Architecture 乾淨架構。
Clean Architecture 乾淨架構
Clean Architecture 並不像是 MVC、MVP、MVVM 這類架構,關注於資料處理過程中各角色之間的關係,而是從更高層的視角,去規範整個程式各個 features 內外的依賴關係。
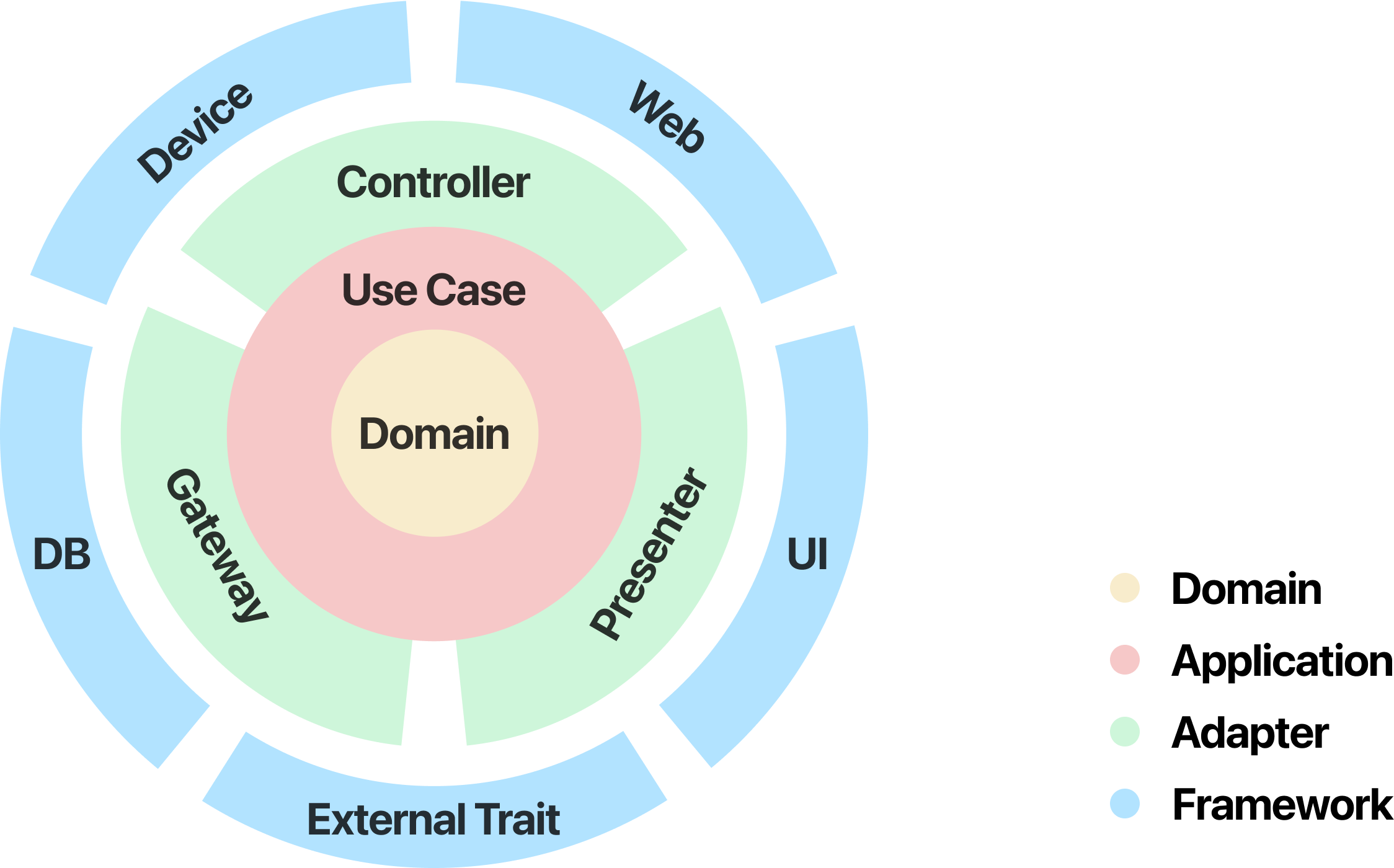
上圖是解釋 Clean Architecture 非常經典的同心圓,這個架構最核心的原則就是:所有的依賴關係都必須由外到內,即內層不知道外層的一切。接下來將會以 rust actix-web 後端為例,從 API 請求到資料庫,介紹每一層的職責以及實作範例。
Framework - API Route
負責接收外部請求(如 HTTP API),將請求轉交給對應的 Controller。這一層通常不包含業務邏輯,只做請求分發與錯誤碼處理。
pub fn configure_post_routes(cfg: &mut web::ServiceConfig) {
cfg.service(
web::scope("/post")
.route("", web::post().to(create_post_handler))
);
}
pub async fn create_post_handler(
post_controller: web::Data<dyn PostController>,
post_dto: web::Json<CreatePostRequestDto>,
) -> impl Responder {
let result = post_controller
.create_post(post_dto.into_inner())
.await;
match result {
Ok(post) => HttpResponse::Created().json(post),
Err(e) => {
match e {
PostError::InvalidTitle => HttpResponse::BadRequest().finish()
_ => HttpResonse::InternalError().finish()
}
}
}
}
Adapter - Controller, DTO
Controller 負責協調請求與 Use Case 的互動,DTO(Data Transfer Object)則用來封裝輸入/輸出資料,避免外部格式直接影響內部邏輯。
#[derive(Deserialize, Clone)]
pub struct CreatePostRequestDto {
pub title: String,
pub content: String,
pub published_time: Option<String>,
}
impl CreatePostRequestDto {
pub fn into_entity(self) -> Post {
Post {
id: -1,
title: self.title,
content: self.content,
published_time: self
.published_time
.and_then(|time_str| DateTime::parse_from_rfc3339(&time_str).ok())
.map(|dt| dt.with_timezone(&Utc)),
}
}
}
impl PostController {
pub async fn create_post(
&self,
post: CreatePostRequestDto,
) -> Result<PostResponseDto, PostError> {
let post_id = self
.create_post_use_case
.execute(post.into_entity())
.await?;
self.get_post_by_id(id, Some(user_id)).await
}
}
Application - Use Case
這一層實作具體的業務流程,調用 Domain 物件完成需求。Use Case 不依賴外部框架,僅依賴 Domain 與 Gateway 介面。
在這邊你會看到我們似乎呼叫了外層的 Repository 來進行資料存取,稍後會介紹依賴反轉原則,以保持正確的依賴關係。
impl CreatePostUseCase {
pub async fn execute(&self, post: Post) -> Result<i32, PostError> {
post.validate()?;
self.post_repository.create_post(post).await
}
}
Domain - Entity
Domain 層定義核心商業邏輯與實體(Entity),這些物件純粹描述業務規則,不依賴任何外部元件。
struct Post {
pub id: i32,
pub title: String,
pub content: String,
pub published_time: Option<DateTime<Utc>>
}
impl Post {
pub fn validate(&self) -> Resule<(), PostError> {
if self.title.len() > 64 {
return PostError::InvalidTitle
}
return ();
}
}
Adapter - Gateway
Gateway 負責將 Use Case 需要的外部資源(如資料庫、API)抽象成介面,並提供實作。
impl PostRepository for PostRepositoryImpl {
async fn create_post(&self, post: Post) -> Result<i32, PostError> {
self.post_db_service
.create_post(PostDto::from(post))
.await
}
}
Framework - Database
這一層負責實際與資料庫、第三方服務等外部系統溝通,實作 Gateway 介面。
impl PostDbService for PostDbServiceImpl {
async fn create_post(&self, post: PostDto) -> Resule<i32, PostError> {
sqlx::query_scalar!(
r#"
INSERT INTO "post" (title, content, published_time)
VALUES ($1, $2, $3)
RETURNING "id"
"#,
post.title,
post.content,
post.published_time,
)
.fetch_one(&self.db_conn)
.await
.map_err(|e| PostError::DatabaseError)
}
}
維持依賴關係最重要的技巧:依賴反轉
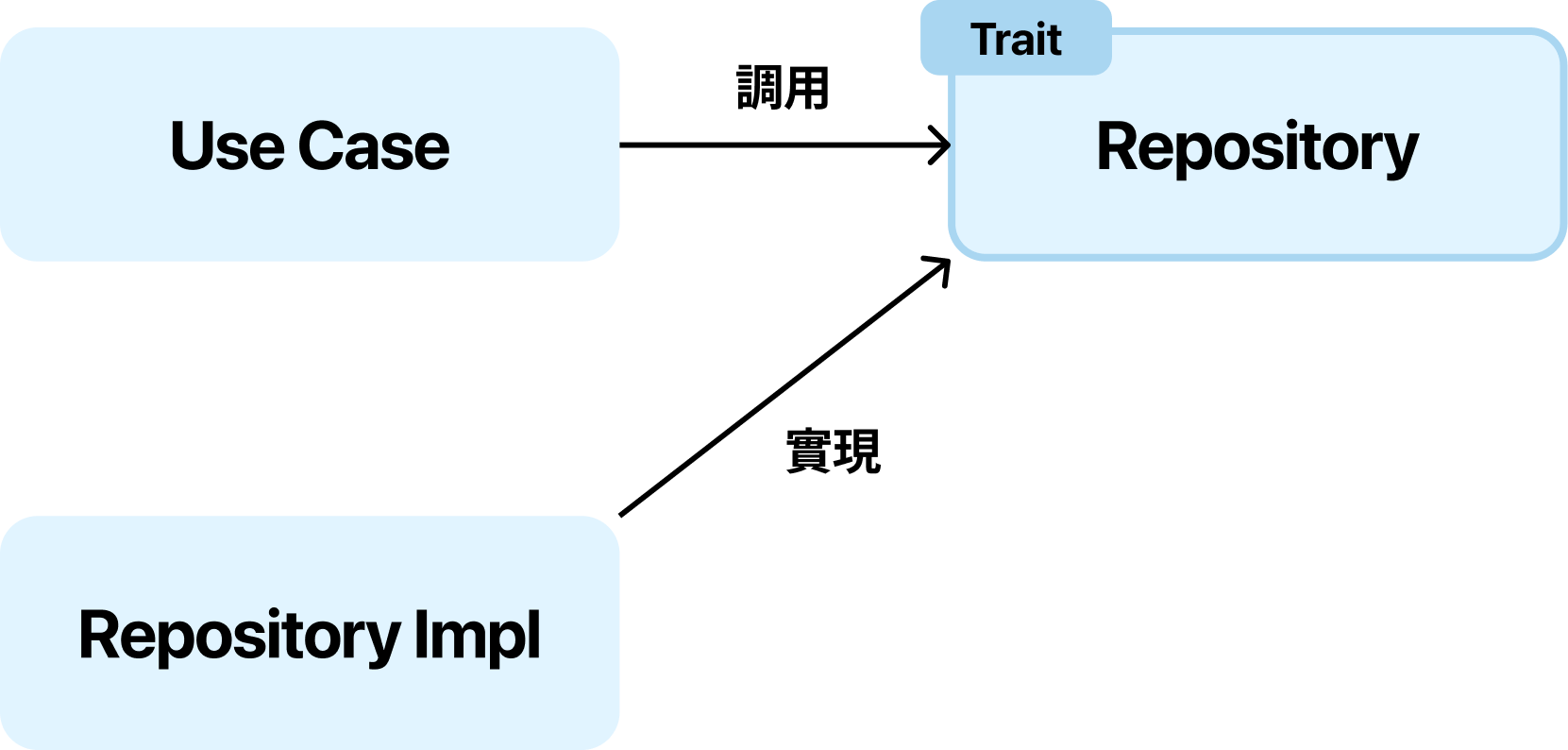
經過上面各層的說明後,一定會有一個疑惑:內層回傳的資料,勢必得從外層取得,這樣是不是違反了一開始提到「由外到內」的依賴關係了呢?這就是我們需要依賴反轉原則 (Dependency Inversion Principle) 的地方。
依賴反轉原則就是 SOLID 原則中的 D,它告訴我們:
- 高層模組不應該依賴低層模組,兩者都應該依賴抽象
- 抽象不應該依賴細節,細節應該依賴抽象
在 Clean Architecture 中,我們通過定義接口(大多數語言為 interface,Rust 稱之為 trait)來實現這一點。例如,Use Case 層需要訪問數據庫,但它不直接依賴數據庫實現,而是依賴一個抽象的 Repository 接口。這個接口定義在 Use Case 層,而實現則在外層的 Gateway 中。
// 在 Application Layer 定義 Repository 的介面
#[async_trait]
trait PostRepository {
async fn create_post(&self, post: Post) -> Result<i32, PostError>;
}
struct CreatePostUseCase {
// Use case 依賴的是同一層定義的介面
post_repository: Arc<dyn PostRepository>,
}
impl CreatePostUseCase {
pub async fn execute(&self, post: Post) -> Result<i32, PostError> {
self.post_repository.create_post(post).await
}
}
struct PostRepositoryImpl;
// 在 Adapter Layer 中實現 Repository
#[async_trait]
impl PostRepository for PostRepositoryImpl {
async fn create_post(&self, post: Post) -> Result<i32, PostError> {
...
}
}
通過這種方式,依賴關係被反轉了:不是 Use Case 依賴 Repository 實現,而是 Repository 實現依賴 Use Case 定義的接口。這確保了內層不知道外層的細節,保持了依賴方向的一致性。
Clean Architecture 能為我們帶來什麼?
-
業務邏輯不再被任何框架或資料庫綁架
由於在 Clean Architecture 中,所有依賴關係都是向內的,同時與外部世界互動的部分,如 API Endpoints、資料庫都是在最外層實作。如此一來,我們可以在不影響業務邏輯的情況下,輕易的替換任何類型的框架或是資料庫。
-
抽象介面帶來極致的可測試性
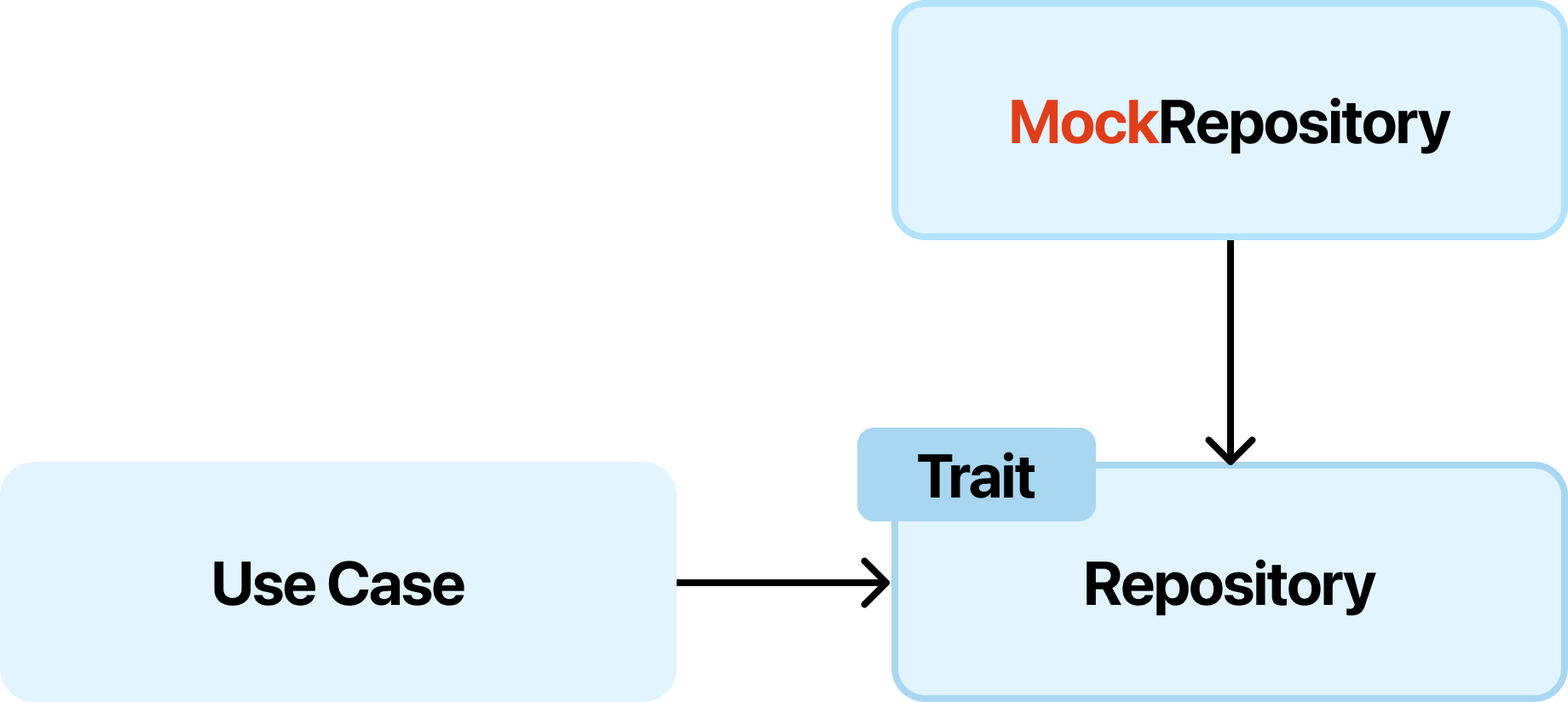
由於依賴反轉,我們可以輕鬆地模擬(mock)外部依賴,進行單元測試。例如,測試 Use Case 時,我們可以提供一個模擬的 Repository 實現,而不需要實際訪問數據庫。
-
專案結構有了明確的規範,所有人有了共同語言
採用 Clean Architecture 之後,專案的分層與責任劃分變得非常清晰,無論是新進同事還是跨部門協作,都能快速理解每一層的職責與邊界。這種結構化的規範,讓大家在討論需求、設計或是除錯時,都有一致的語言與依據,大幅降低溝通成本,也讓專案更容易維護與擴展。
從混亂到優雅的轉變並非一蹴而就,而是需要團隊共同努力和持續改進的過程。ATDD 幫助我們明確需求和驗收標準,Clean Architecture 則提供了一個可持續發展的代碼結構。兩者結合,能夠有效地應對複雜業務需求的挑戰,讓我們的專案不再失控。
記住,架構設計的目的不是為了追求完美的代碼,而是為了更好地服務業務需求和團隊協作。在實際應用中,需要根據項目特點和團隊情況做出適當的調整和取捨。最重要的是,保持代碼的可測試性、可維護性和可擴展性,讓系統能夠從容應對未來的變化。
通過擁抱 ATDD 和 Clean Architecture,我們可以告別隕石式開發,迎來更加可控、可預測的開發過程,讓專案從混亂走向優雅。